Dostoyevsky Idiot — python object
We’re going to jsonify and objectify great creation of Fyodor Dostoyevsky – The Idiot.
We’ll get well structured data ready for further experiments.

We have “The Idiot” text.
That’s top level function to objectify this text:
def objectify_idiot(url=TEXT_URL):
text = requests.get(url).text
idiot = {
'title': 'The Idiot',
'author': 'Fyodor Dostoyevsky',
'text': text}
part_seps = ['PART {}'.format(roman.toRoman(i)) for i in range(4, 0, -1)]
part_seps.append('Copyright')
parts = re.split('|'.join(part_seps), text)
idiot['copyright'] = parts[-1].strip()
parts = [p.strip() for p in parts[1:-1]]
idiot['parts'] = [objectify_part(p, n + 1) for n, p in enumerate(parts)]
return idiot
objectify_part() and others low level functions implementation can be found here.
Run pip install git+https://github.com/boorstat/python-boorstat.git to install python package with ready to use functions:
from boorstat.lit.dostoyevsky.idiot import idiot
idiot_as_dict = idiot.objectify_idiot()
idiot_as_dict_from_pregenerated_json = idiot.from_json()
Final structure can be understood from pregenerated json.
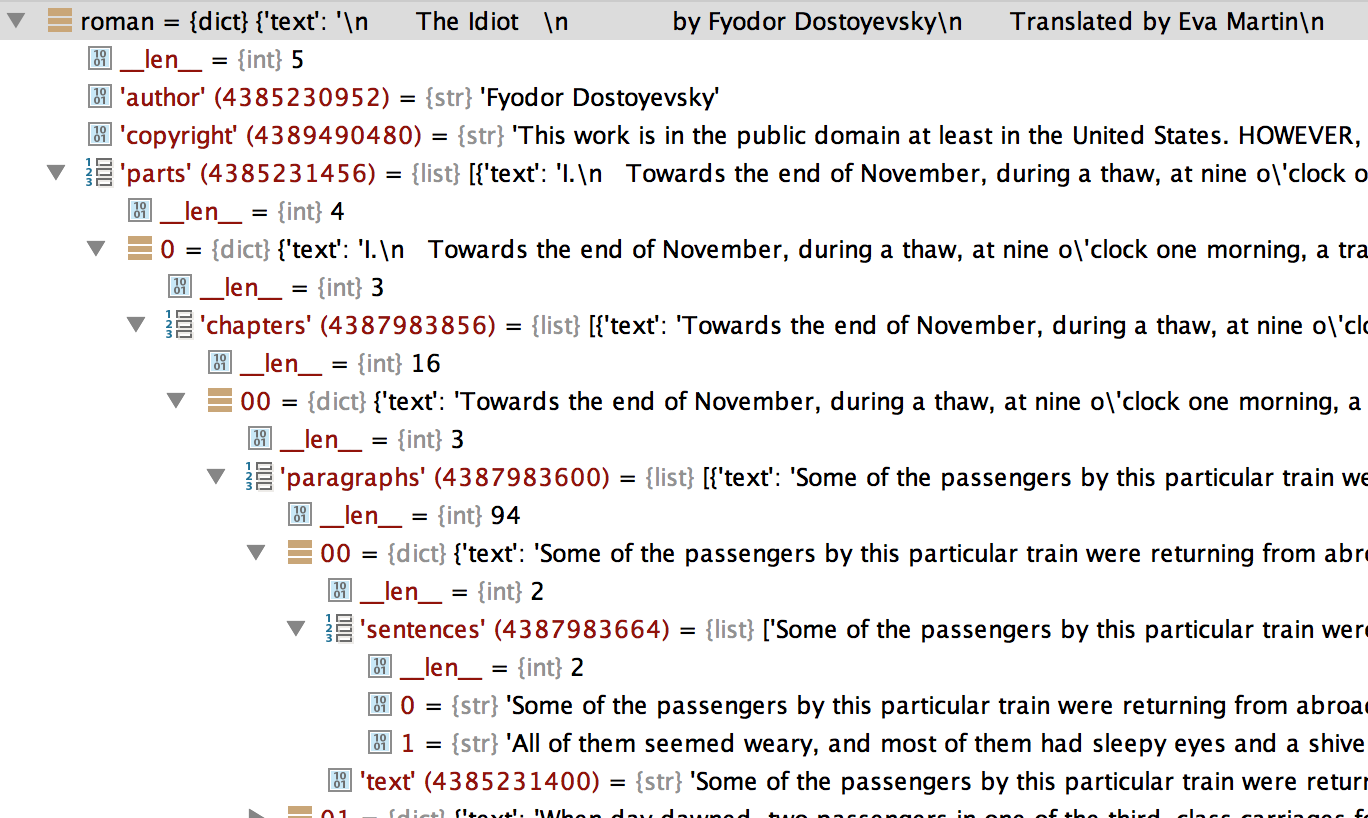
Also this screenshot from debugger can clarify hierarchy inside “The Idiot” object: